Git Going With GitKraken
Our team over at the SOPS Lab has been writing a lot of code lately as part of an ongoing effort to make our AmoebotSim simulator publicly available through an open source release. There’s a lot of diversity in coding/software engineering experience among our team members — from finishing a first course in C++ to completing several internships in big tech — so I’ve been spending some time thinking about how to make on-boarding easier, forming new students into conceptual thinkers and proficient programmers as quickly as possible. This tutorial on the basics of Git is meant to help with that.
Necessary Disclaimers
We have to get two things out of the way up front. First, this is not really the “accessible to anyone, technical or not” kind of post that I usually aim for. While it is meant to be simpler than the average Git tutorial, it’s still going to talk about software skills that are, by nature, technical. Speaking of other Git tutorials: yes, I do know how many Git tutorials already exist. Many of them are ones I’ve learned from and am inspired by. Some are far more complete, more specific, more polished, and even more craftsy than what I intend to do here. The point of this tutorial is to distill all that wonderful material into something that gets students (and other newcomers) acquainted with basic Git concepts and comfortable with a great Git client all in one sitting.
As a last bit of housekeeping, I’d like to credit Rachel M. Carmena, whose methodology I’m following quite closely.
Git’s View of the World
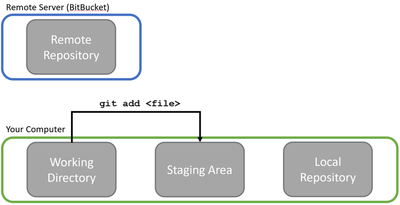
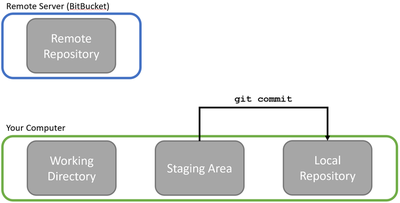
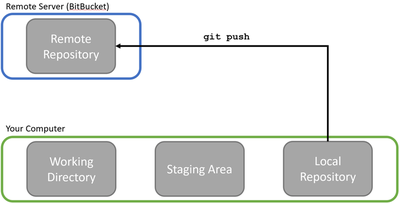
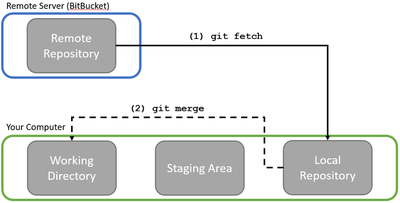
Git sees a software project loosely like this:
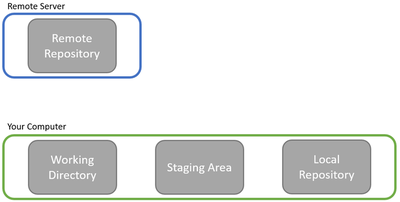
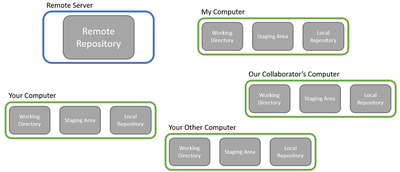
Big picture: there’s the remote server that houses the full software project and all the changes that have been made to it so far, and then there’s your computer where you implement new features and code changes. Now, Git is usually used when writing software collaboratively, so while the above picture is all that you have to worry about, the real setting is more like this:
Hold Up, What’s Git?
Git is just a piece of software that’s openly available for anyone to use. (Aside: it’s not a company or something that’s sold commercially, though this is often confusing because of companies/services like GitHub and GitLab). The problem Git is trying to solve, informally, is to support many people editing the same set of files concurrently while causing as few conflicts and headaches as possible. You might recognize that Google Docs and Dropbox try to solve a similar problem, but with a different strategy that makes them poorly suited for software development. Imagine for a moment that you were trying to use Google Docs for writing real code. Say you’ve been up all night working on a cool new feature, tracking down all its subtle and frustrating bugs, and now you want to compile and test it one last time to make sure it’s all good to go.
But right as you go to compile, your teammate gets in there and starts writing some other code, which naturally isn’t complete yet and doesn’t build! What do you do? Do you hit them up on Slack and ask them to stop coding while you test your feature? (If so, that essentially means only one person can be working at a time). Do you just keep trying to compile over and over until you get lucky and it builds? (If problems arise in testing, you won’t be sure if it’s your code that’s causing issues or someone else’s). This is nightmarish and no one does this. (I hope).
Git is an example of distributed version control software, a type of software meant to make these kinds of situations much easier to handle by giving each user more control over their own version of the files and when to incorporate the changes made by other people. (For the record, there are other choices for distributed version control, but Git is by far the most popular).
Tools of the Trade
In Git, the remote repository contains the current version of the shared code. Remote repositories can be set up on any server (or even your own workstation), but most people prefer to use a service like GitHub, Bitbucket, or GitLab to host their projects for them, which makes life easier. Think of it like this: GitHub is to Git repositories as WordPress is to websites. You can certainly host your own website, but using a service like WordPress saves you the trouble of maintaining a web server yourself. Our team uses Bitbucket for our AmoebotSim project, so that’s what’ll be in the screenshots.
An additional way to simplify using Git is to get a nice Git client like GitKraken or GitHub Desktop instead of interfacing with Git on the command line (which many hardcore users will tell you is the only way to really learn Git). Using the website analogy again, Git clients are to Git repositories like themes and rich-text editors are to websites. Could you put a stellar website together writing your own HTML, CSS, and JavaScript? Sure. Would you learn a lot more about how websites work doing it this way? Of course. But it takes a lot longer, and there’s much more room to make mistakes. In general, Git clients make understanding your repository a breeze with nice graphical representations and controls. I’ll be using GitKraken here, and I highly recommend you do too!
Cloning a Repository
Getting a copy of a repository from a remote server onto your machine is called cloning a repository.
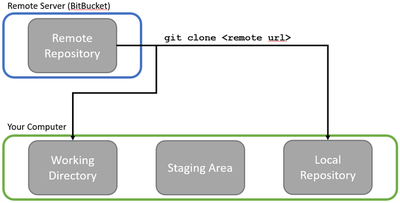
Cloning makes a copy of the remote repository to your local repository. This not only includes the most recent version of the files but also the entire version history (list of changes) for every file, who made those changes, when those changes were made, and all the different branches of those files that your collaborators may be working on (we’ll come back to branching in a future post). The clone operation also puts the most recent version of the files in your working directory, where you can open them up in your file system and start making changes.
This is pretty easy to do with GitKraken:
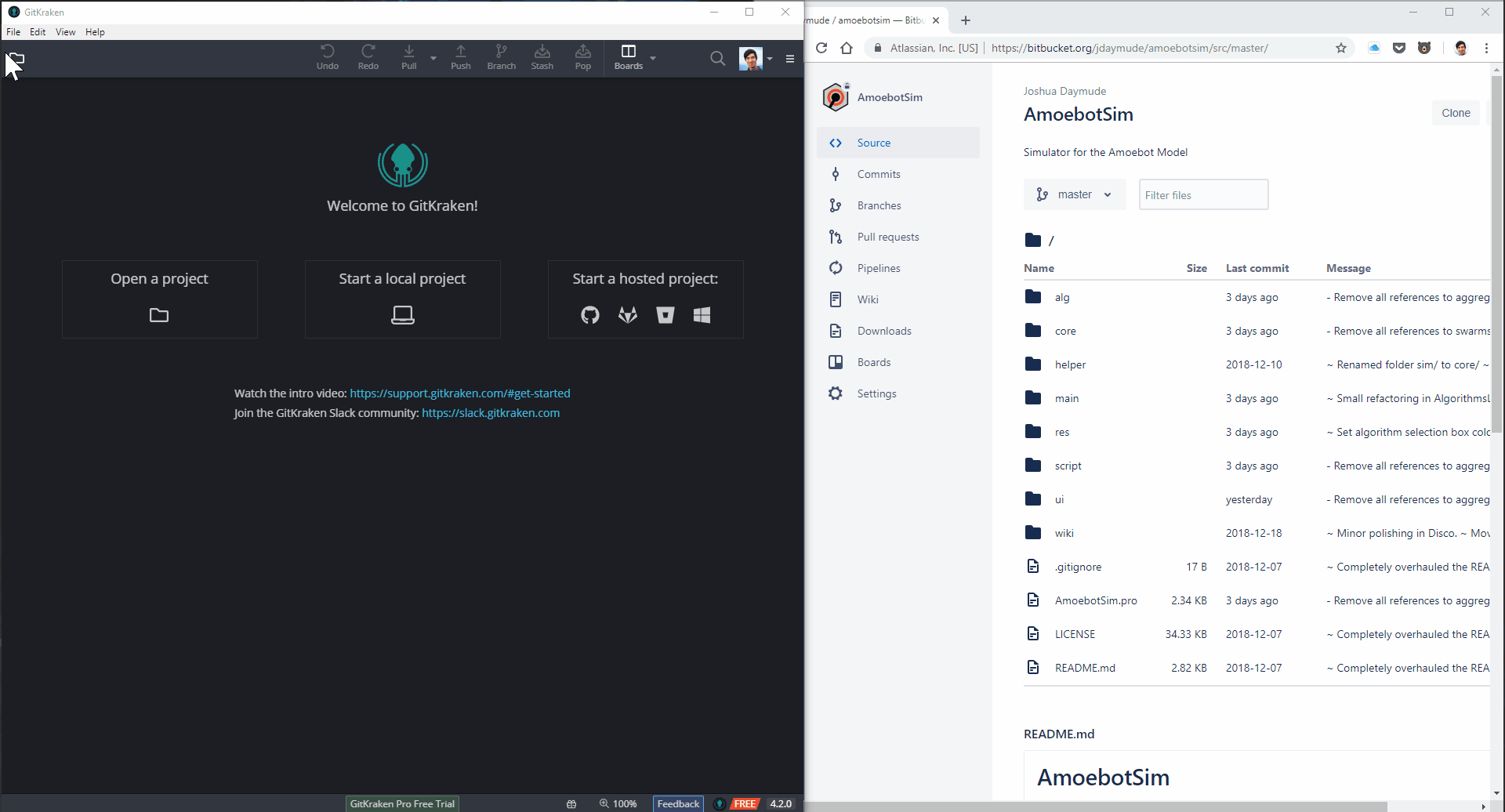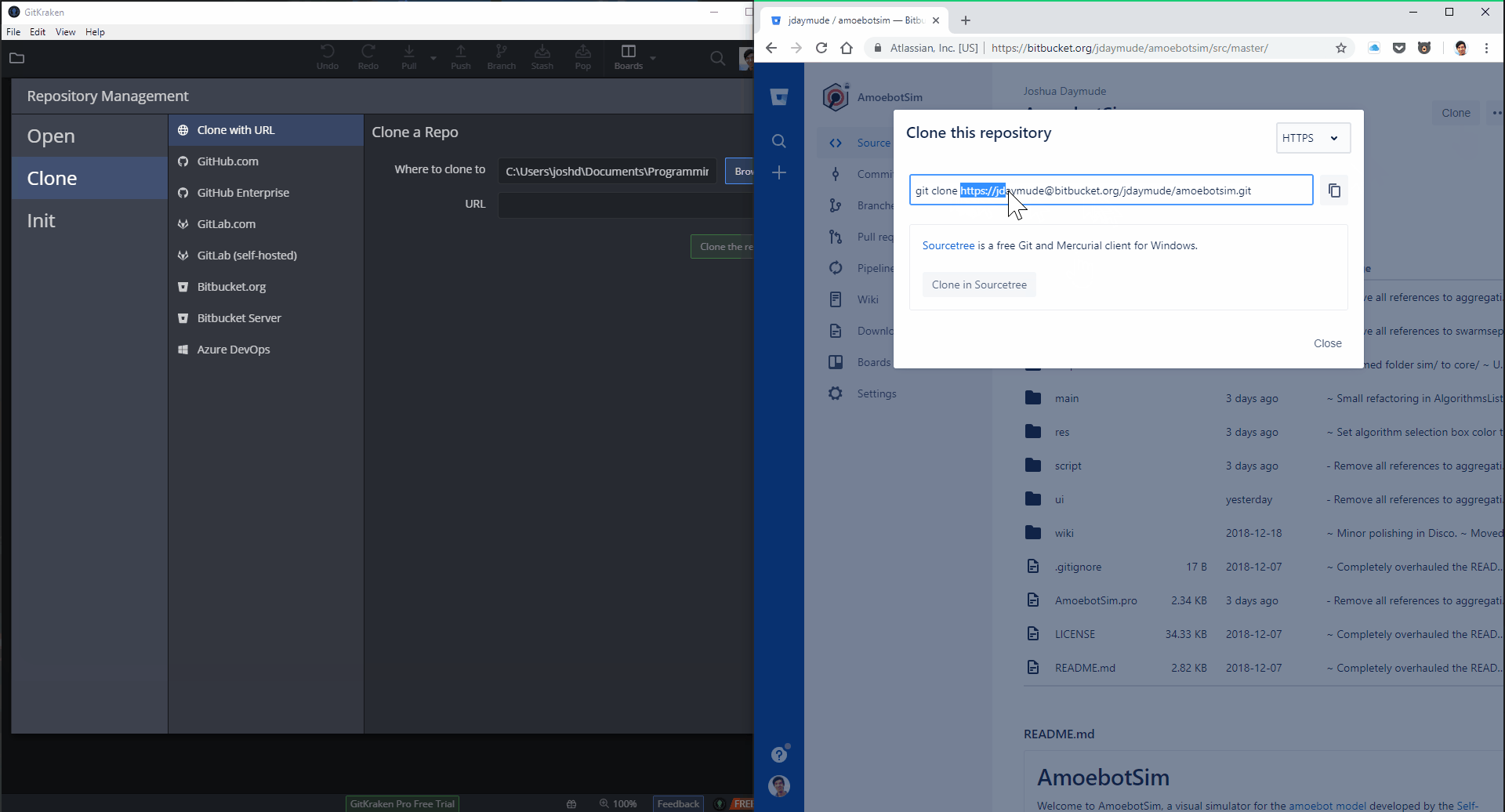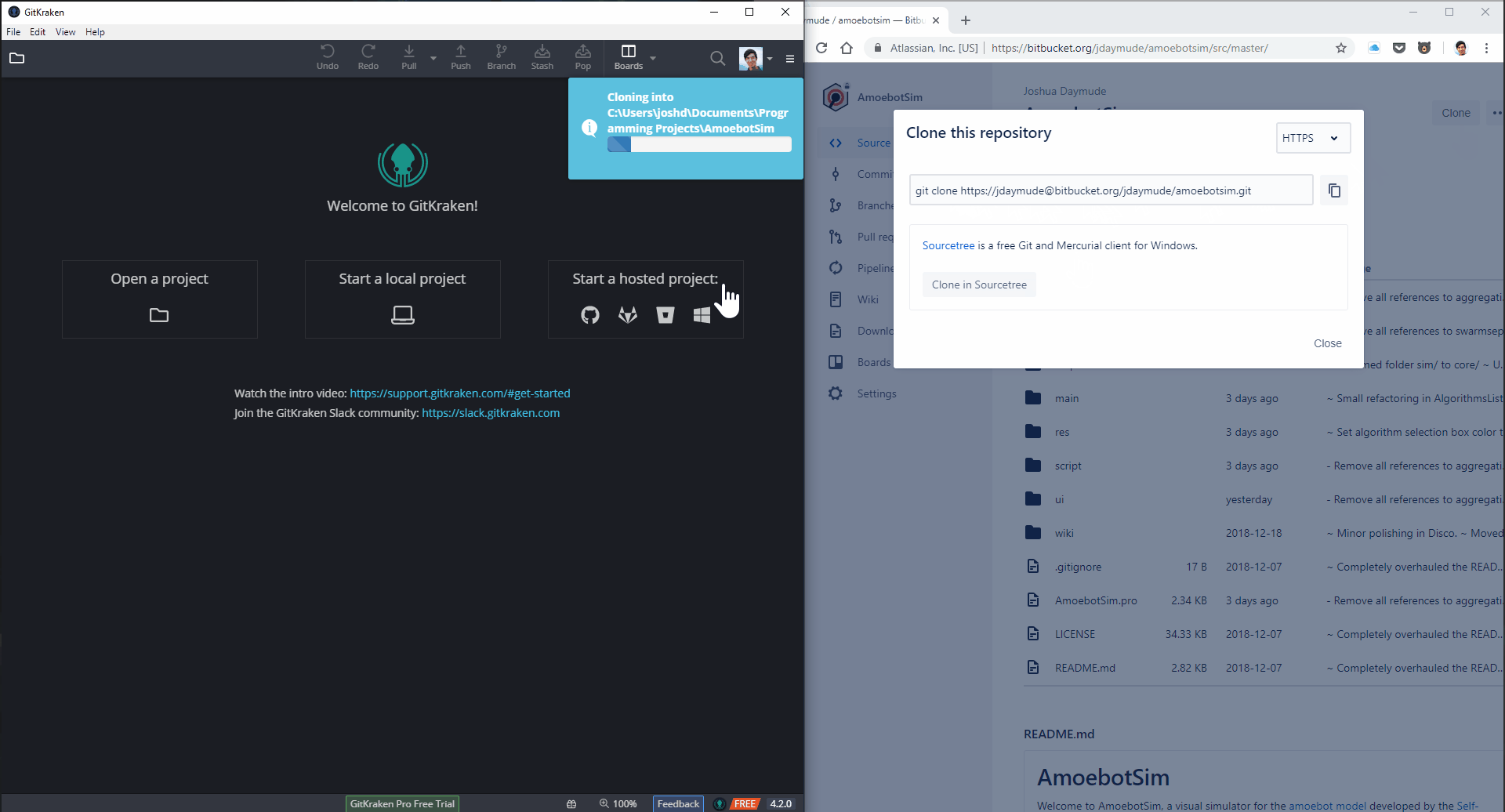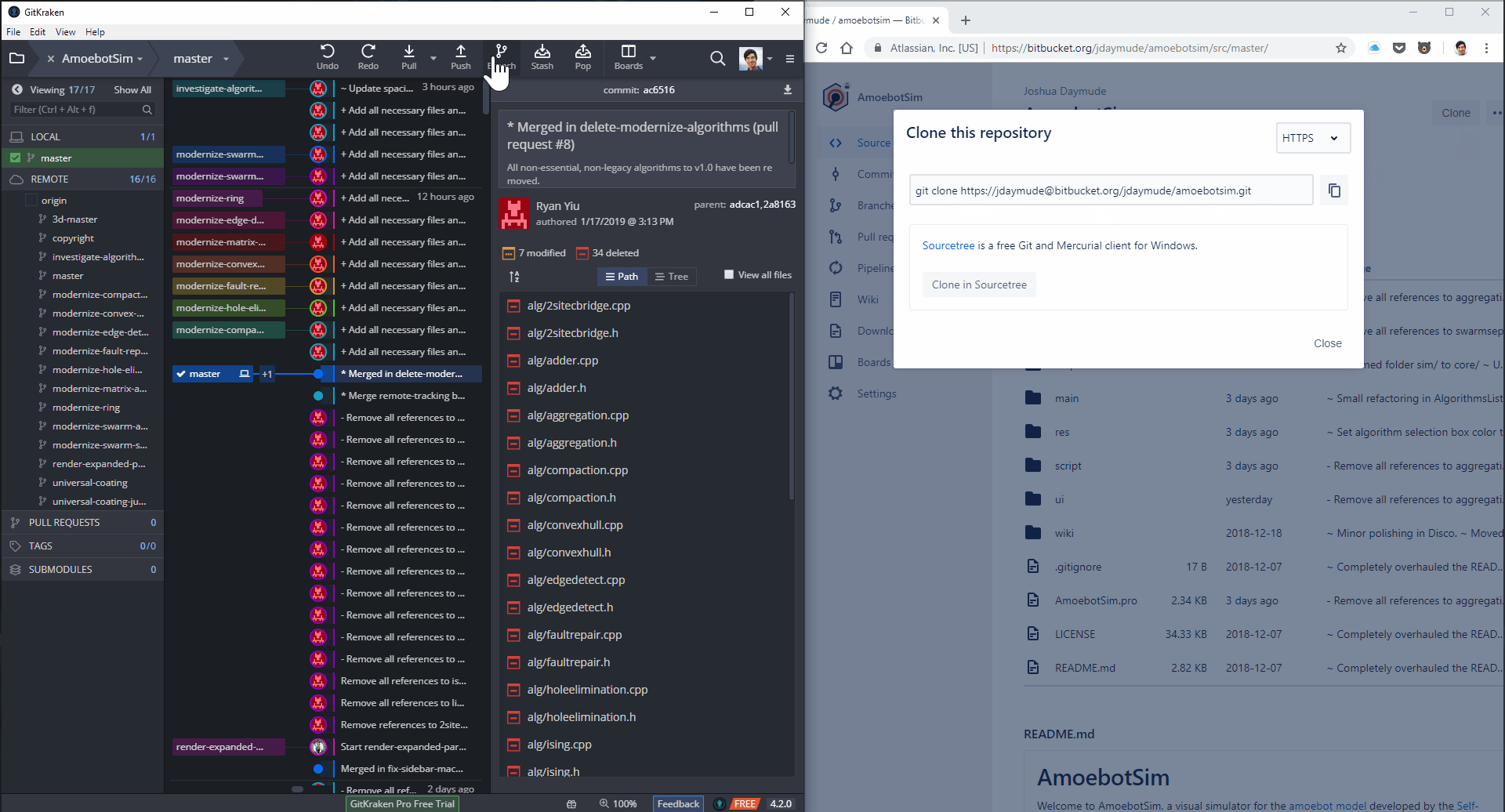
And it’s even easier if you’ve already signed into your hosting platform (e.g., Bitbucket) in GitKraken:
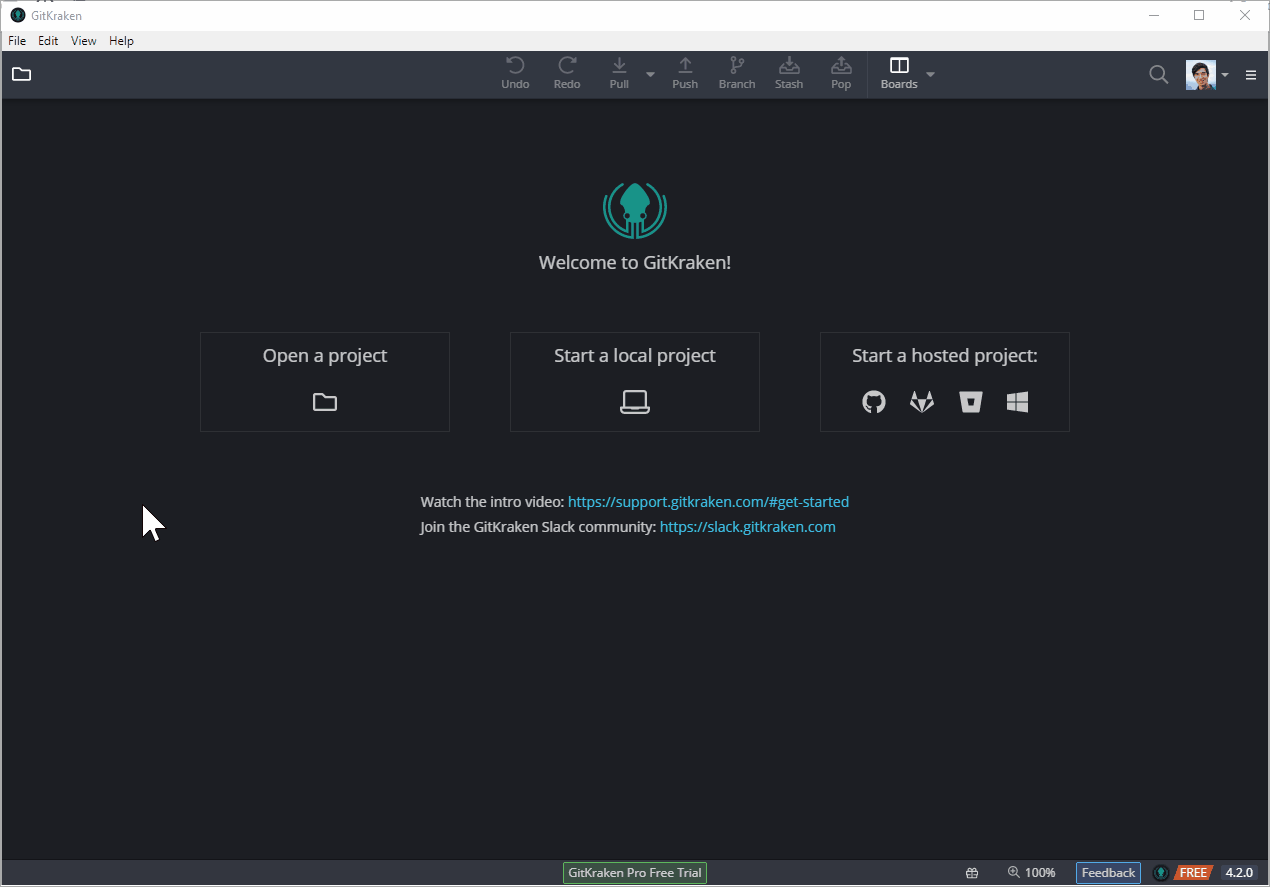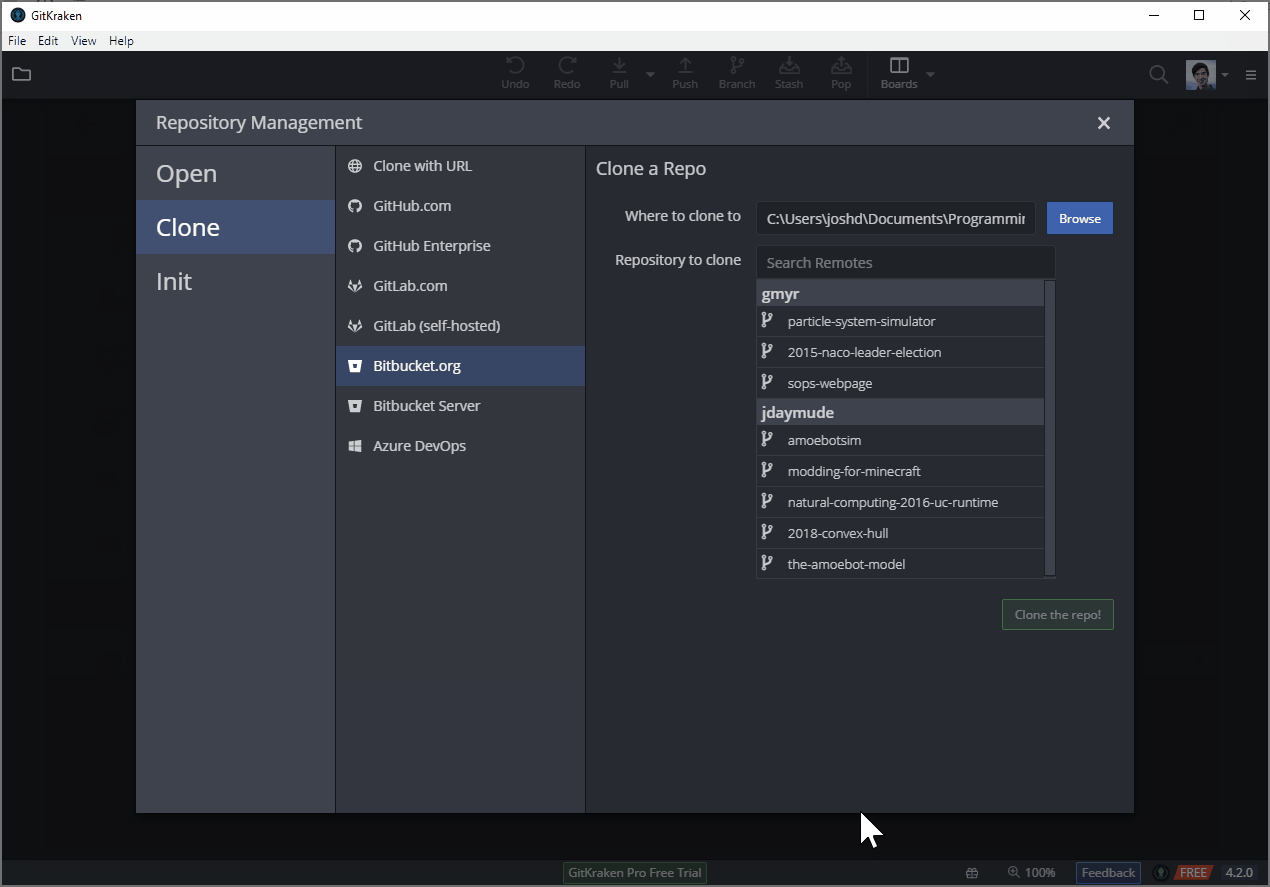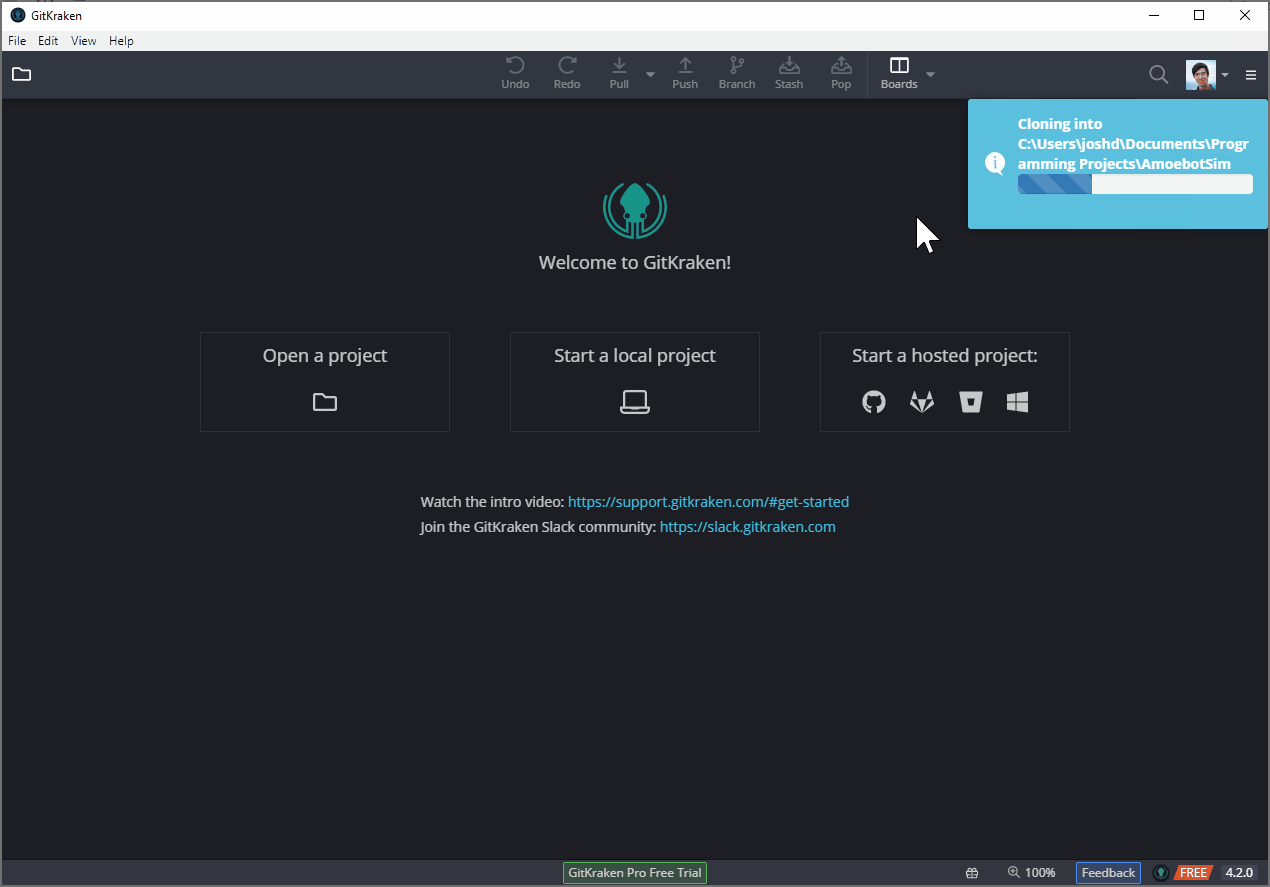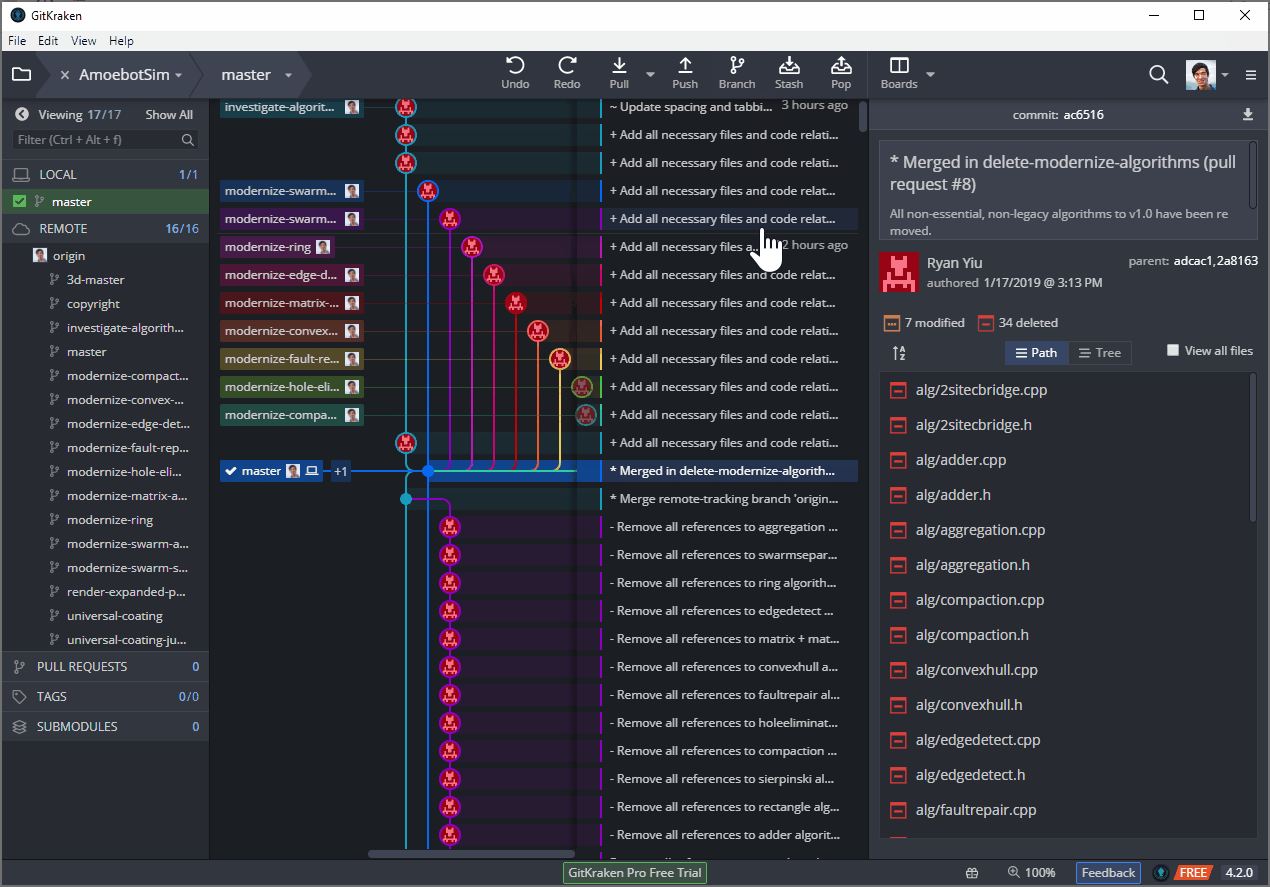
Making and Submitting Changes
Now that the code is in my working directory, I can make my edits. From Git’s perspective, changes can either be tracked, meaning Git knows about them, or untracked, meaning the changes are in new files that haven’t been added to Git yet. Either way, I can add all the changes I’ve made to Git’s staging area in a process called staging:
To illustrate this, I’ll be adding license and copyright information to AmoebotSim (a very important part of going open source). I’ll be making these edits in three parts: (1) adding a LICENSE file, (2) adding a copyright notice to our main.cpp file, and (3) adding an abbreviated copyright notice to the other source files. Adding the LICENSE file will initially be an untracked change (it’s a new file), while the other changes that edit existing files will be tracked.
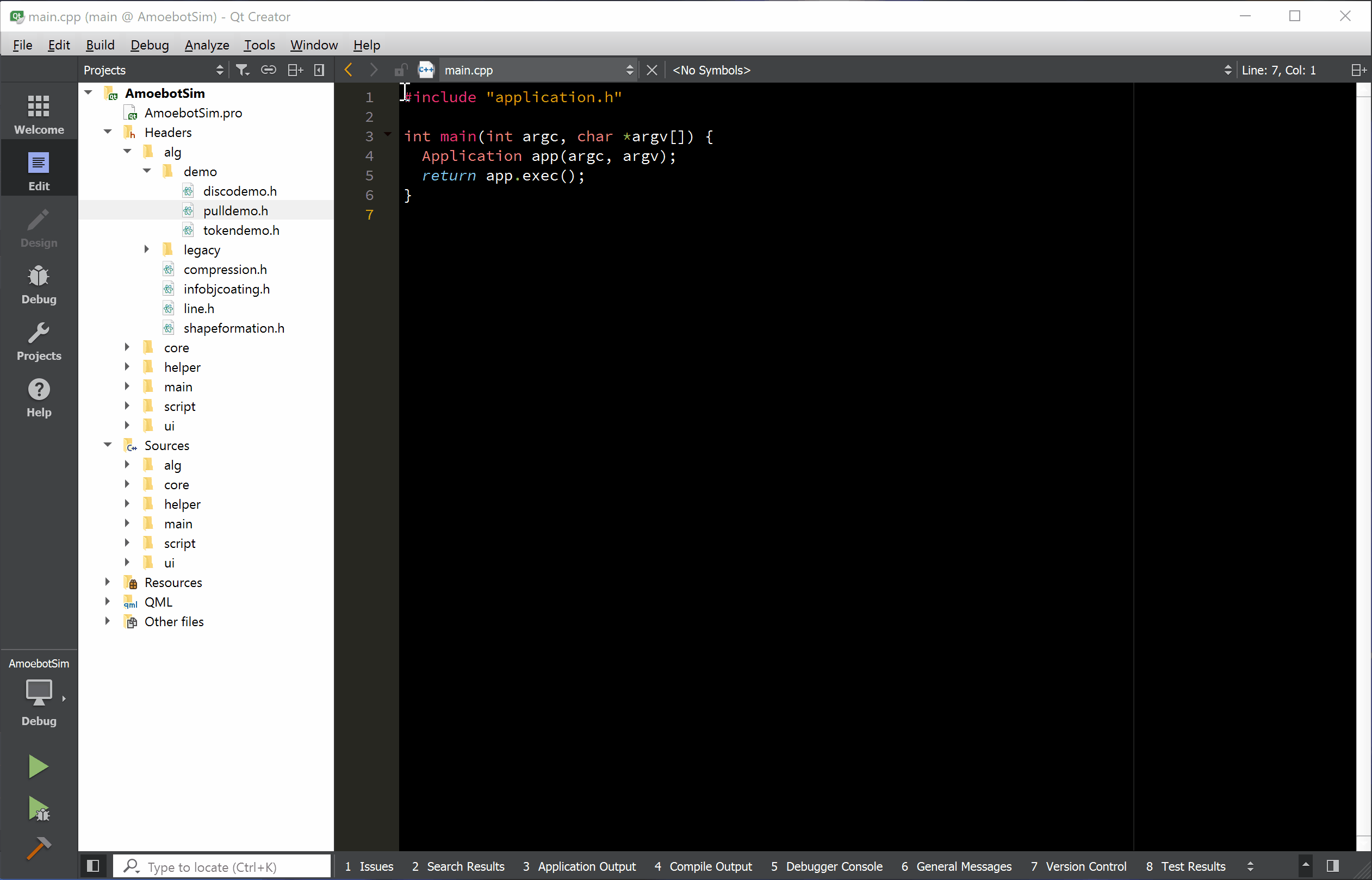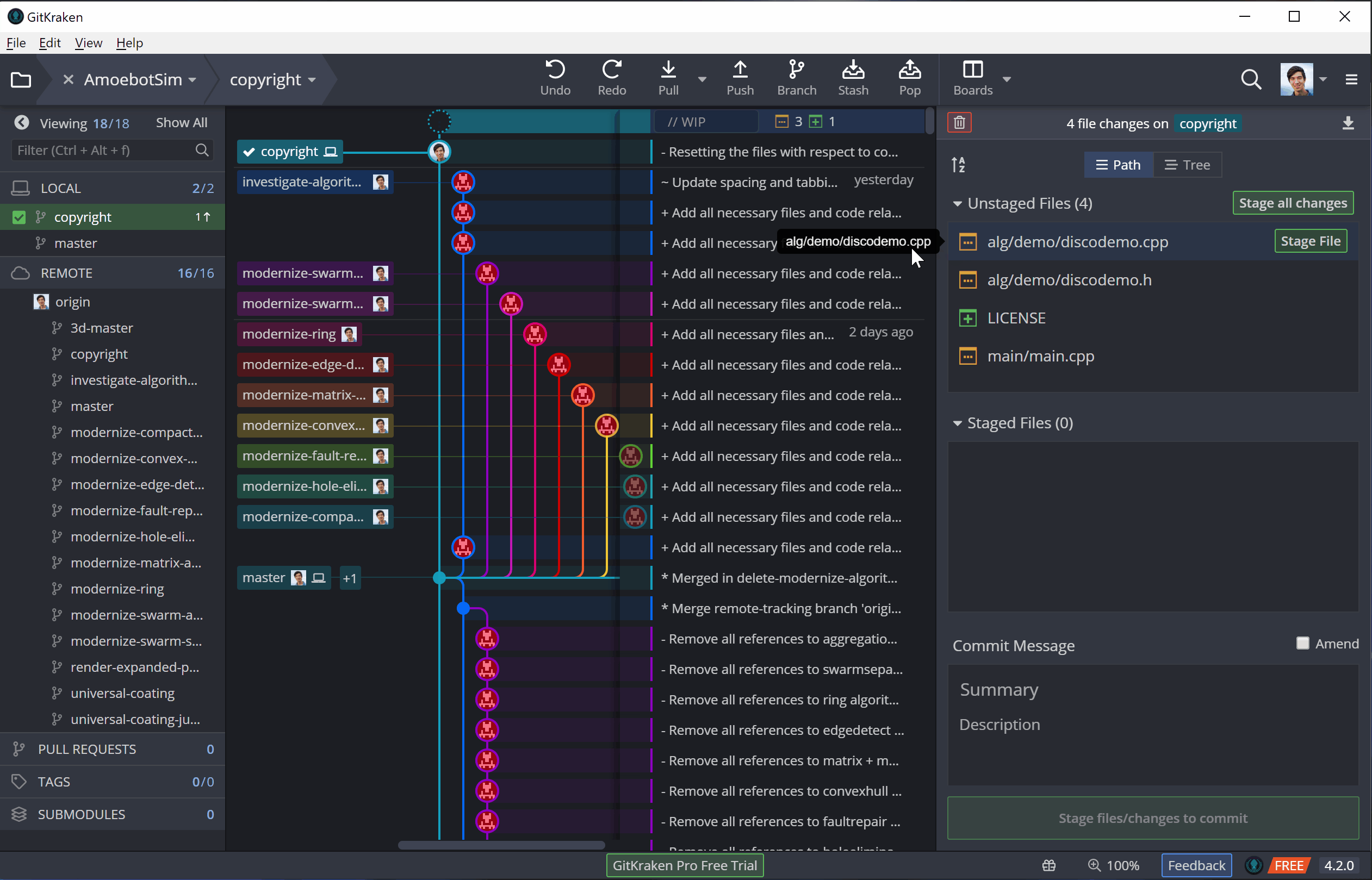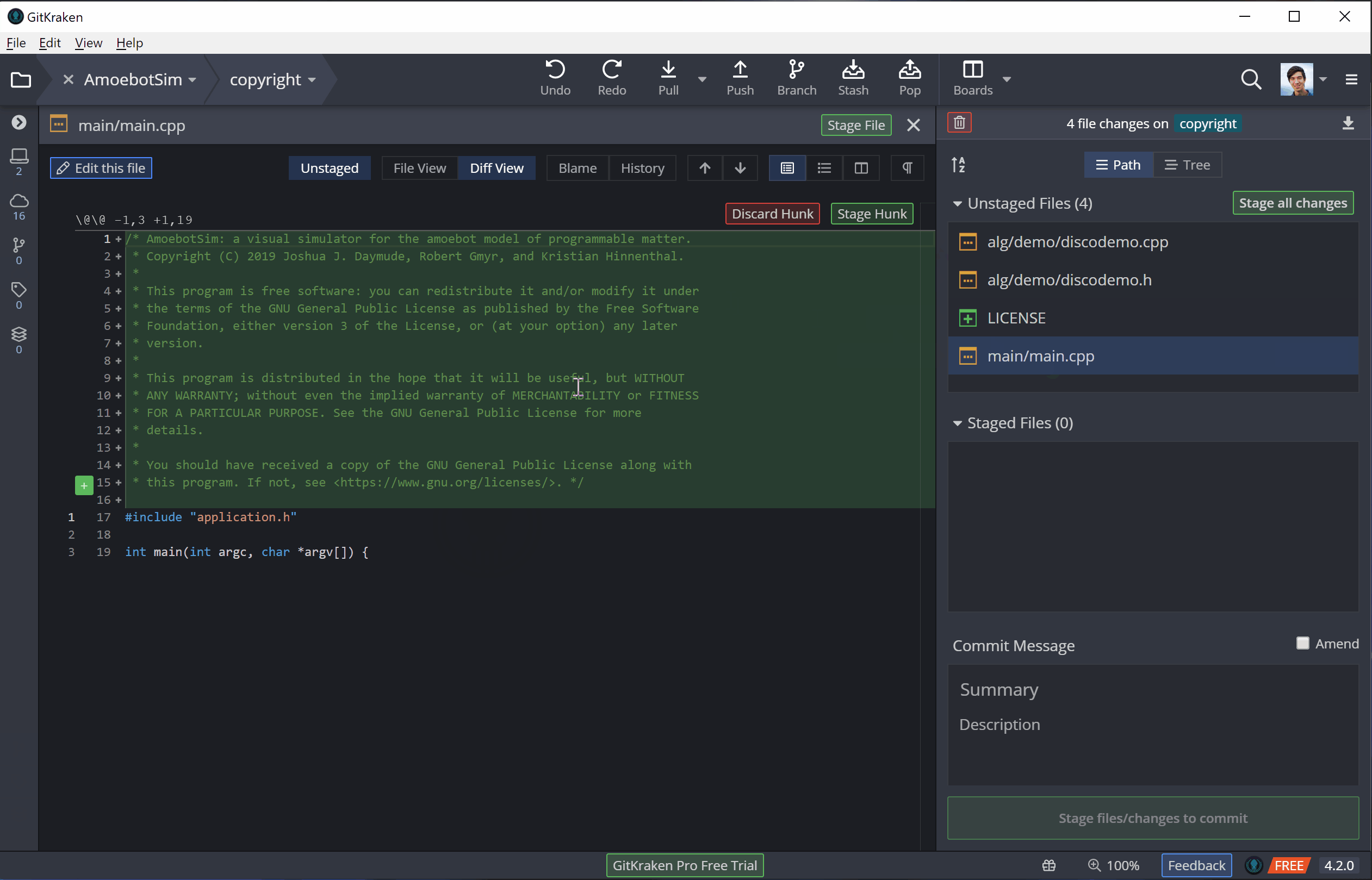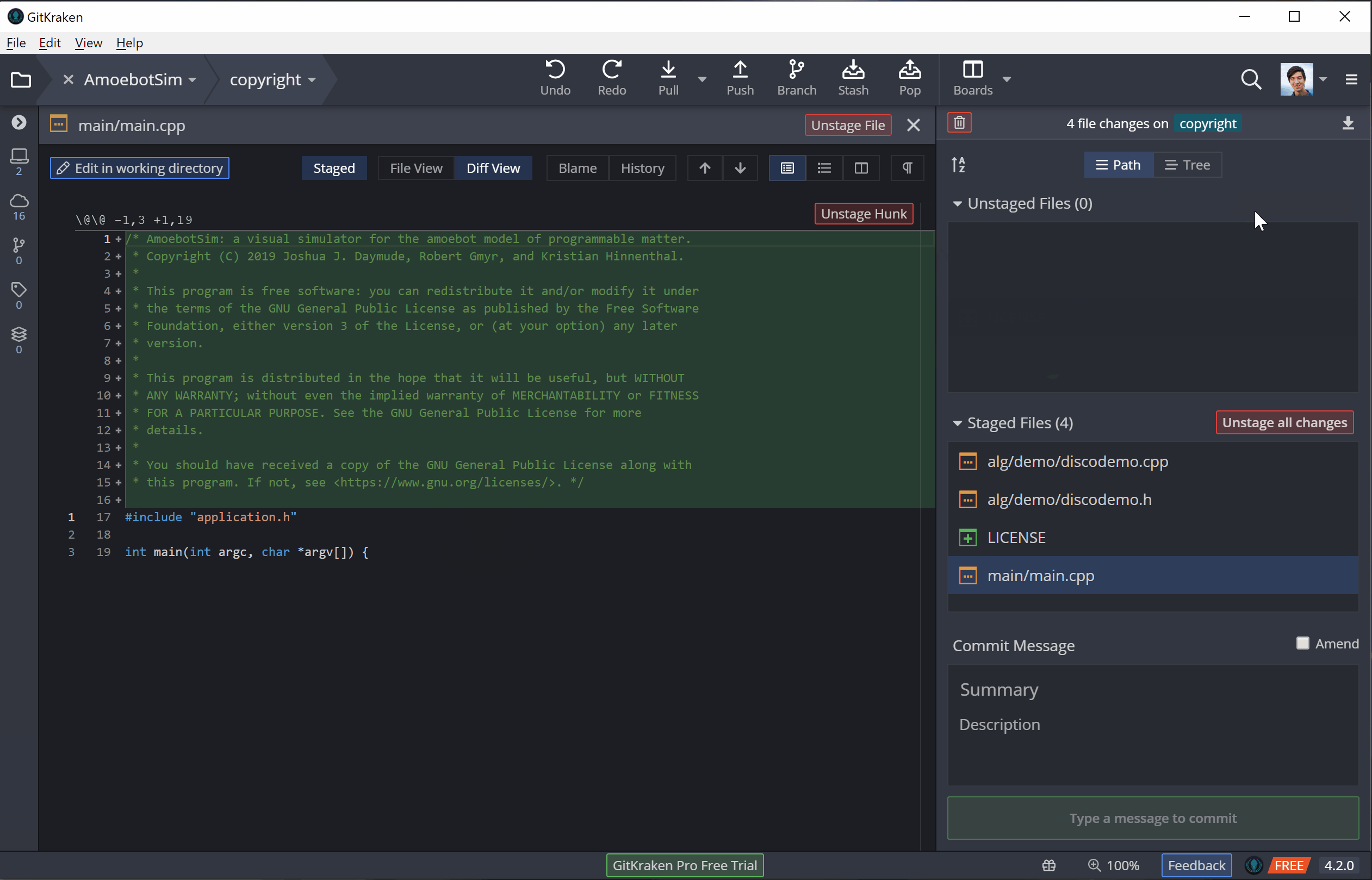
Now that the changes are staged, we can commit them to our local repository. A commit is essentially a batch of changes with a description known as a commit message. In general, a commit message should clearly and concisely describe the changes its commit contains (see this post for best practices). Once that message is done, we can commit, adding our changes to the version history.
This is, per usual, easy to do and visualize in GitKraken:
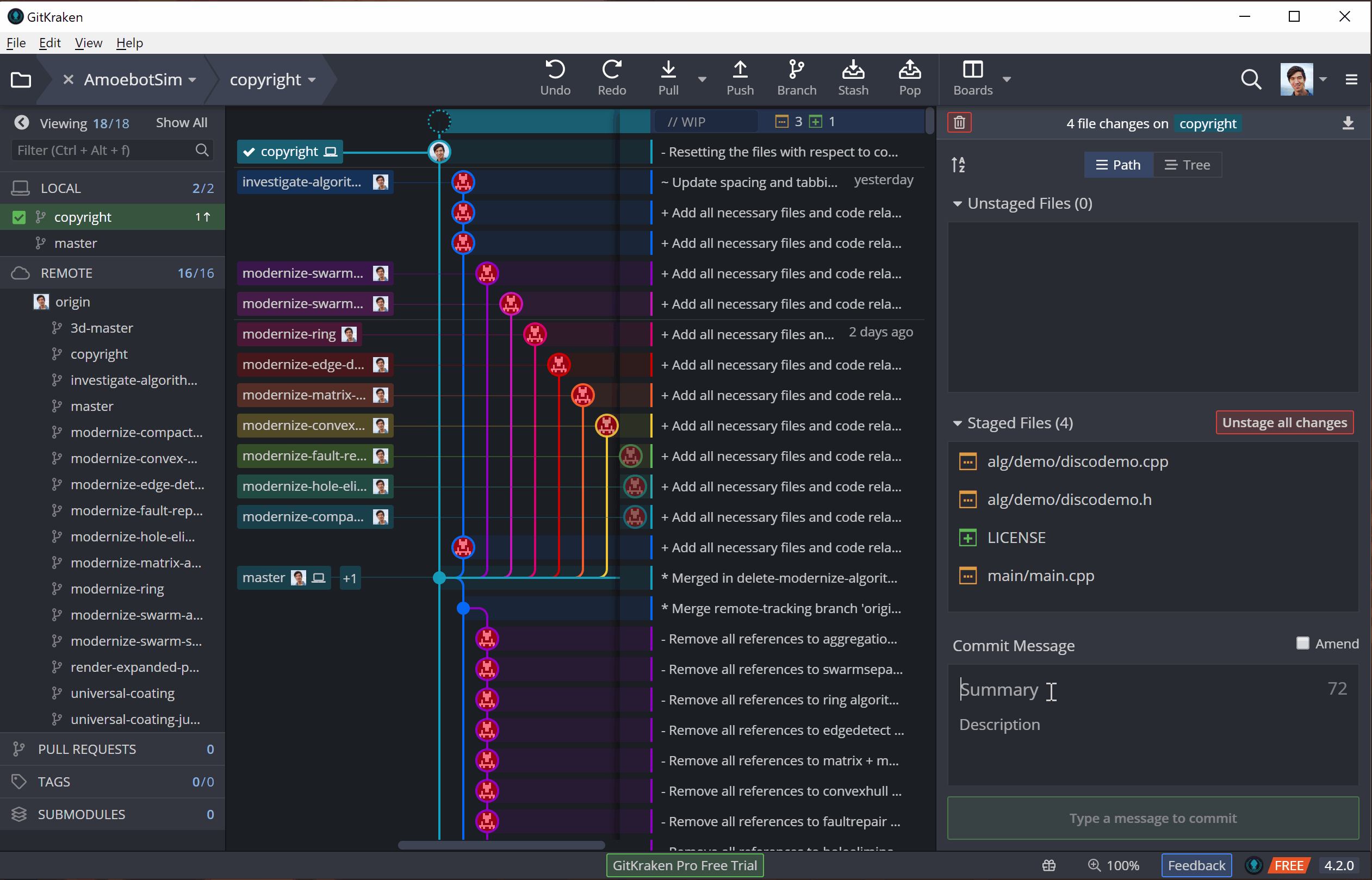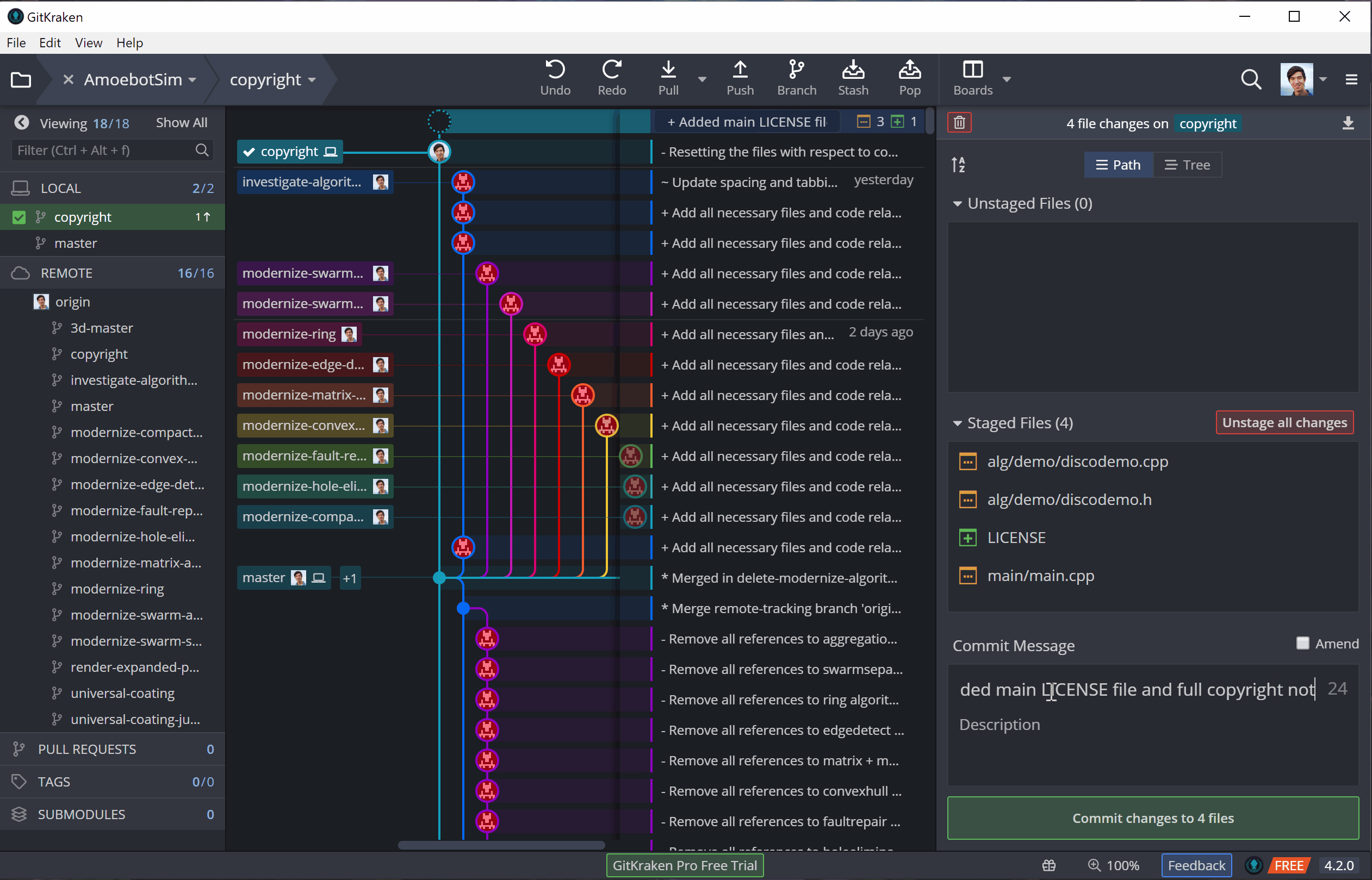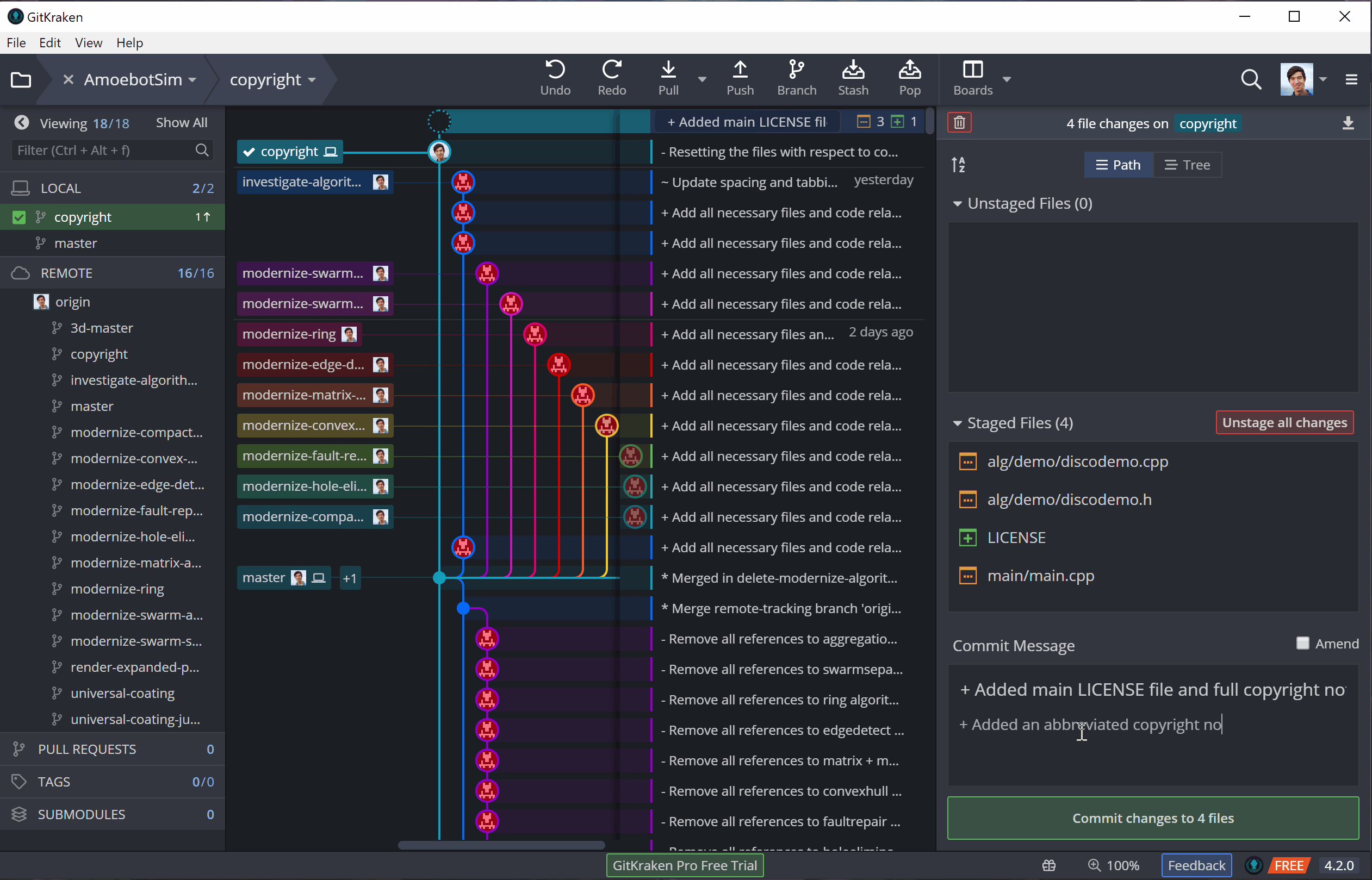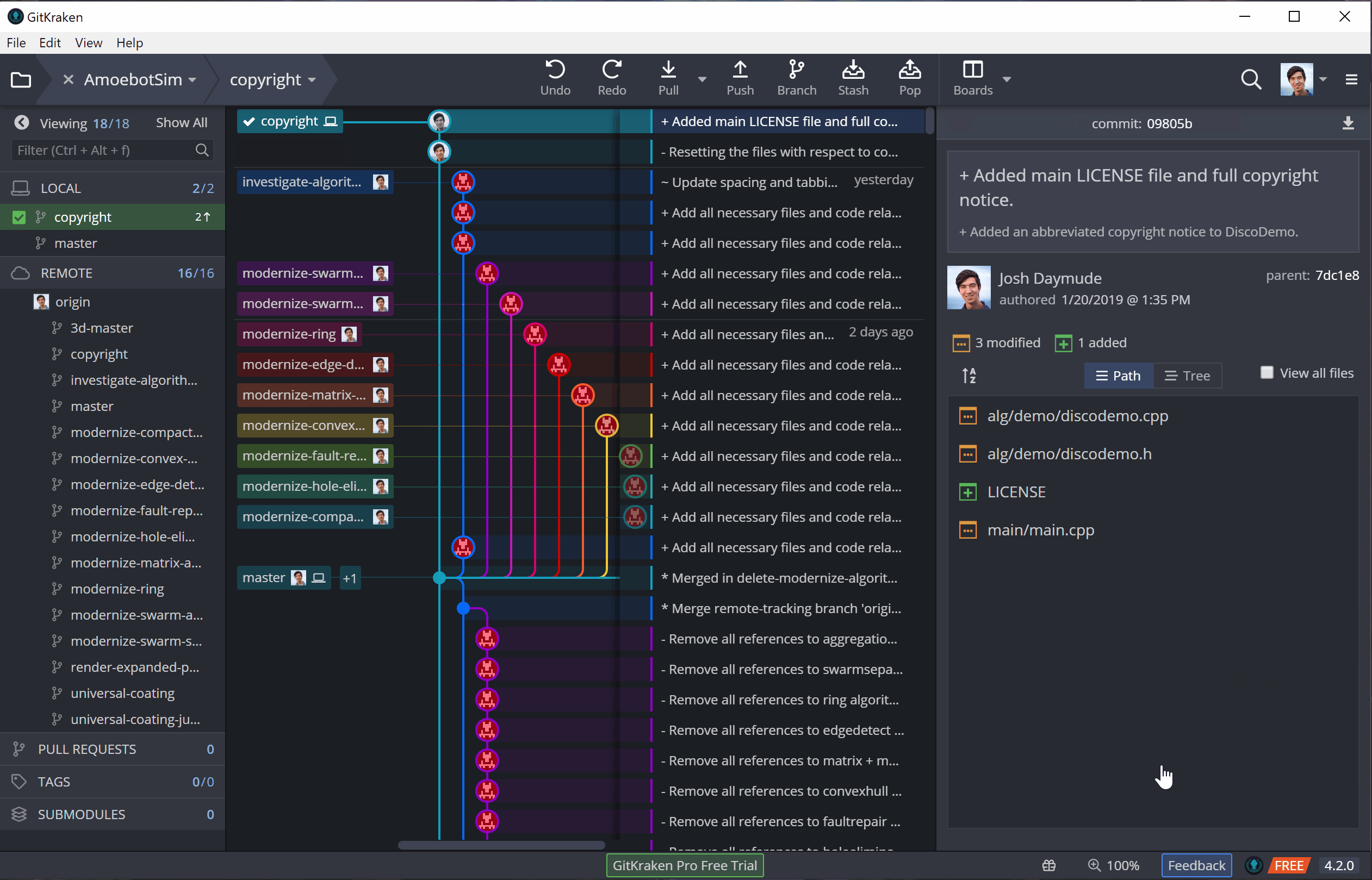
But committing only puts our changes in the local repository (shown by the little computer icon in GitKraken), not the remote repository where everyone else can see them (shown by the profile picture of the repository owner). Updating the remote repository with new commits from our local repository is called pushing.
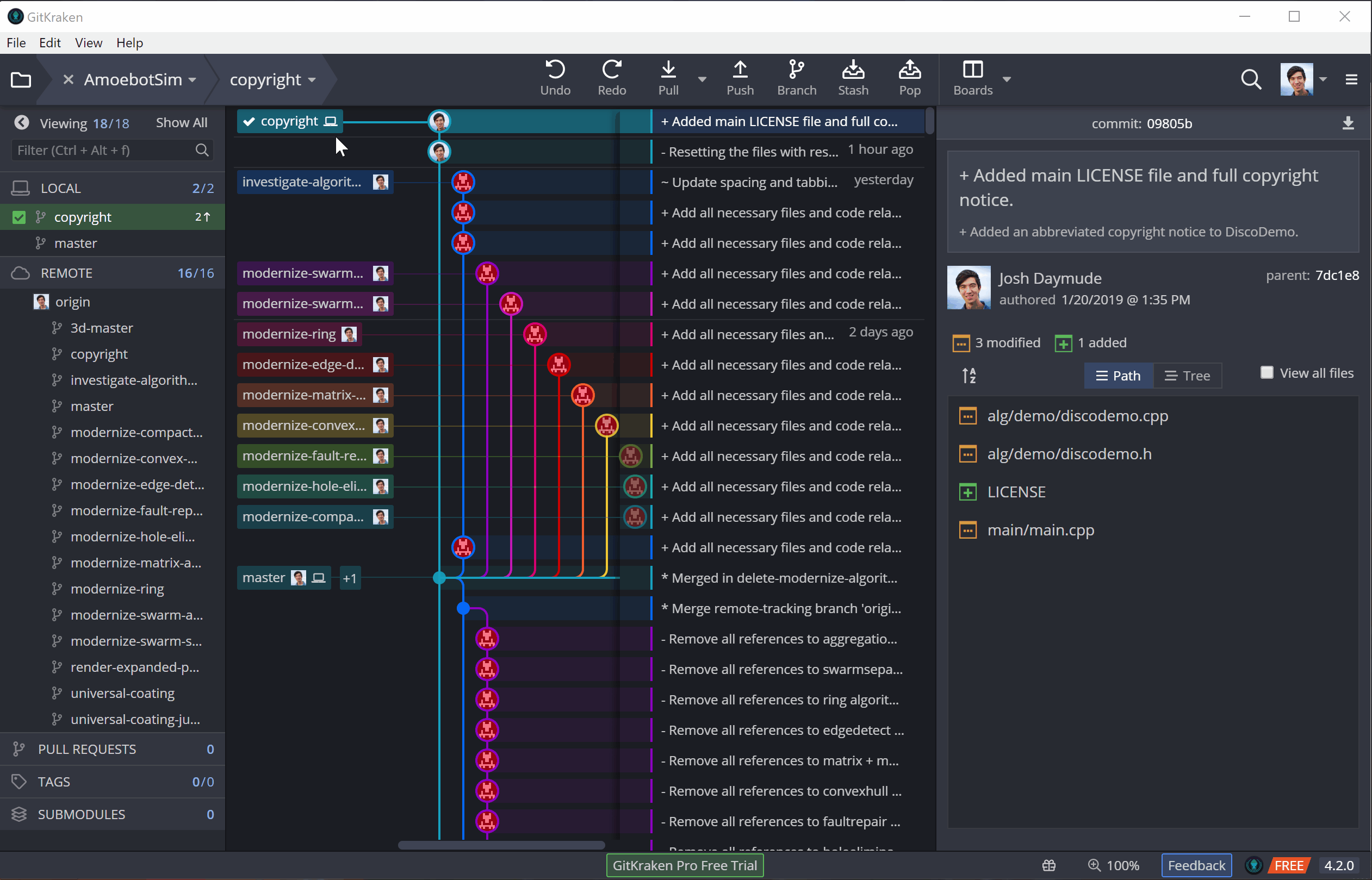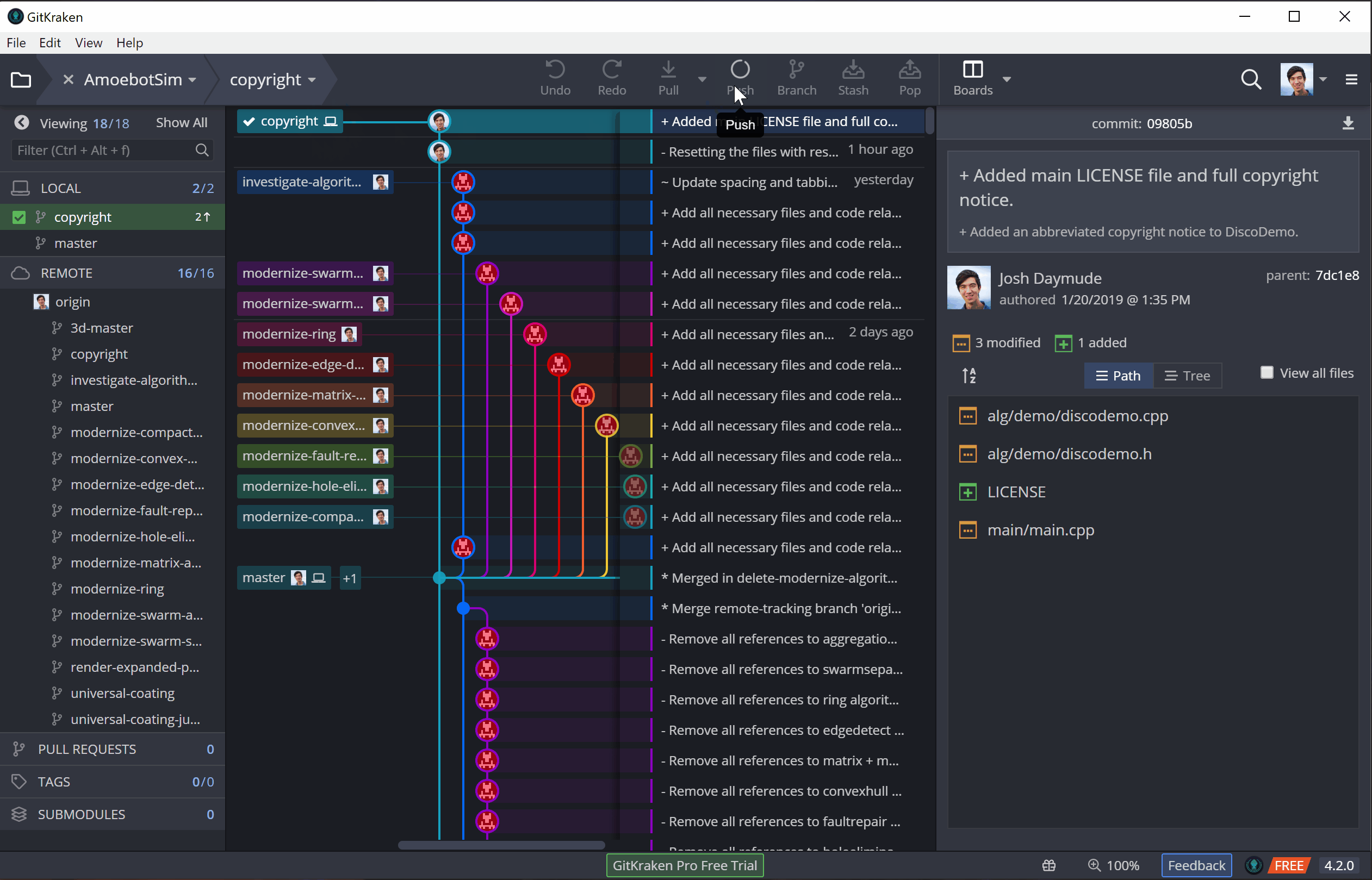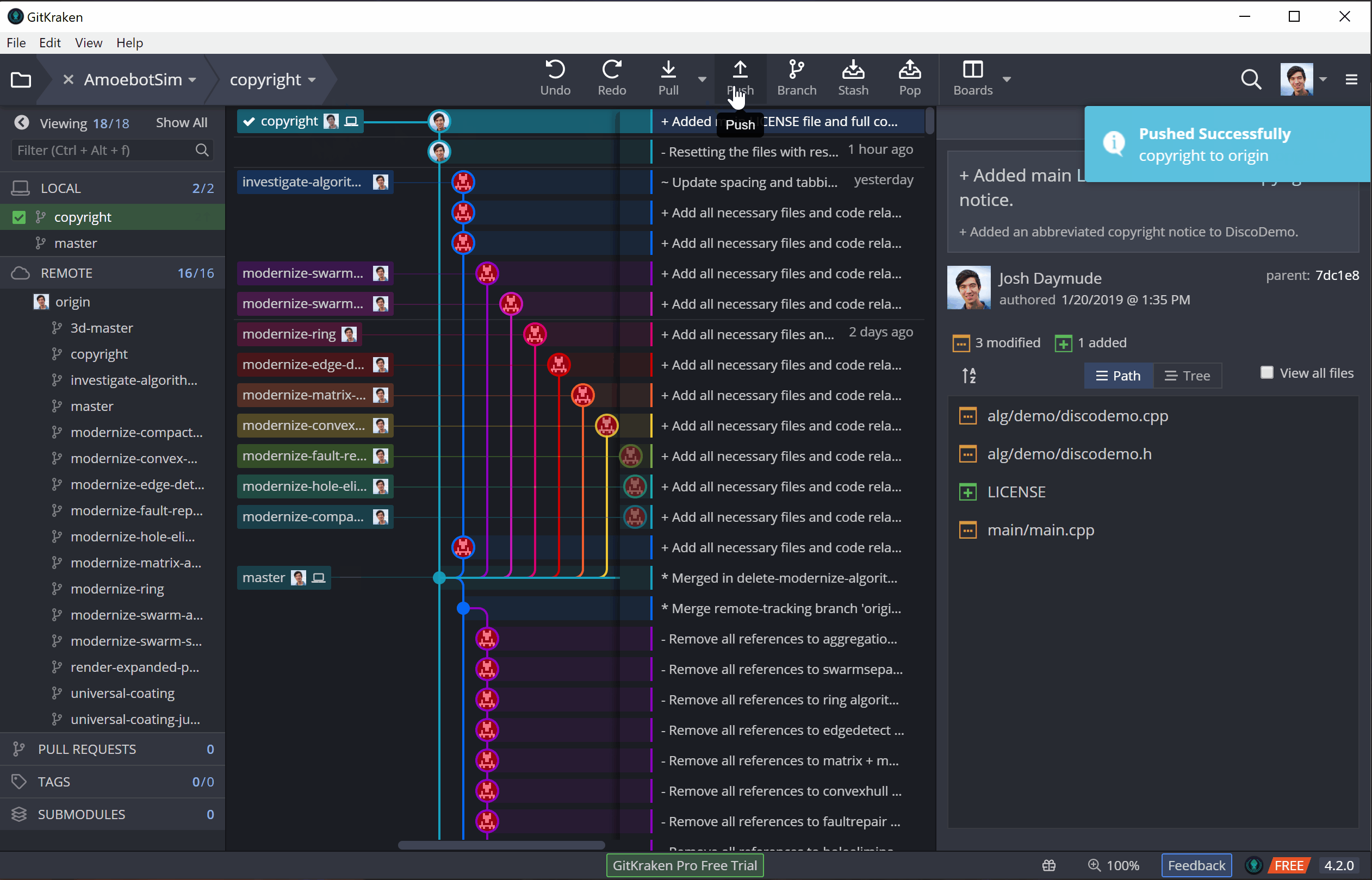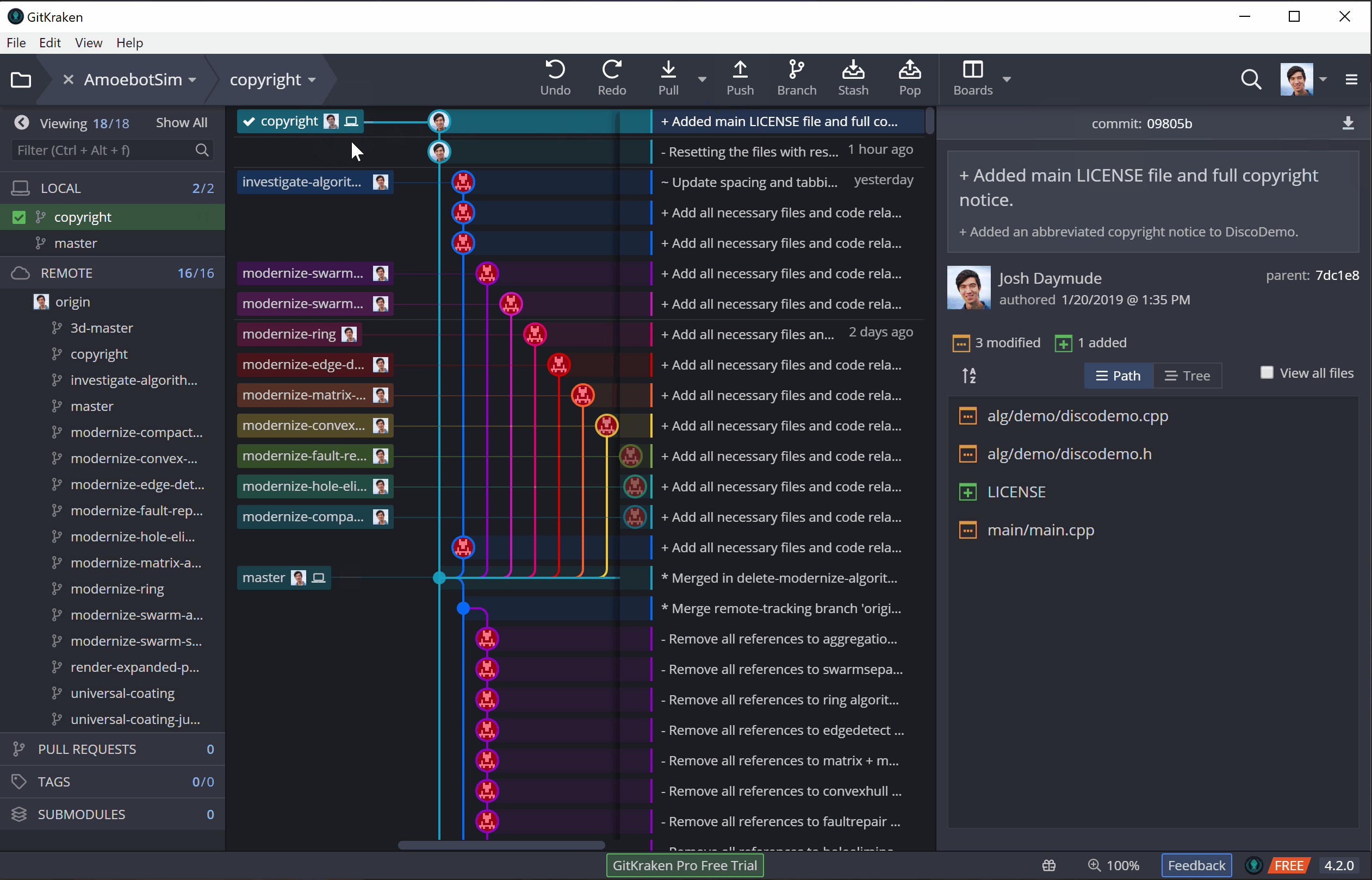
Once commits have been pushed, they’re out there for other repository members to see and use. Be sure that your code builds and is bug-free before you commit and push; otherwise, you’ll break everyone else’s builds and get a lot of angry messages asking you to fix your issues quickly! (There are ways to mitigate these kinds of problems, like branch/fork-based workflows with approval processes, but I’m saving those more advanced topics for a future post).
Getting Other People’s Changes
Say that you were offline for a couple hours (or days…) and are just returning to your project. Your teammates may have committed and pushed code while you were away, and you want to get all their changes. Git gives you two ways to do this: fetch and pull.
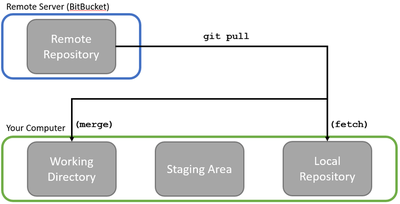
Fetching retrieves all the new updates (commits, files, etc.) from the remote repository and copies them to your local repository. These new updates exist separately from the rest of your work, allowing you to look into them independently from any changes you’ve made locally. If you want your team’s updates to be integrated with your local changes, you’ll need to merge them in.
This can potentially cause merge conflicts if both you and your teammates' commits changed the same lines of code. (Although, to be honest, Git can get confused and think all kinds of things are “conflicts” even when they’re not, so watch out for that). Thankfully, GitKraken has a slick tool for helping you fix your merge conflicts (this was, by far, the #1 reason our team recently switched to GitKraken from Sourcetree):
Pulling simply combines fetching and merging into one step. It retrieves all the new updates from the remote repository and automatically tries to merge them into your local repository, possibly triggering merge conflicts for you to resolve along the way.
In GitKraken, both fetching and pulling can be performed using the top toolbar. The following example shows a pull, though you can see for a brief moment how it first fetches the new commit before merging it in.
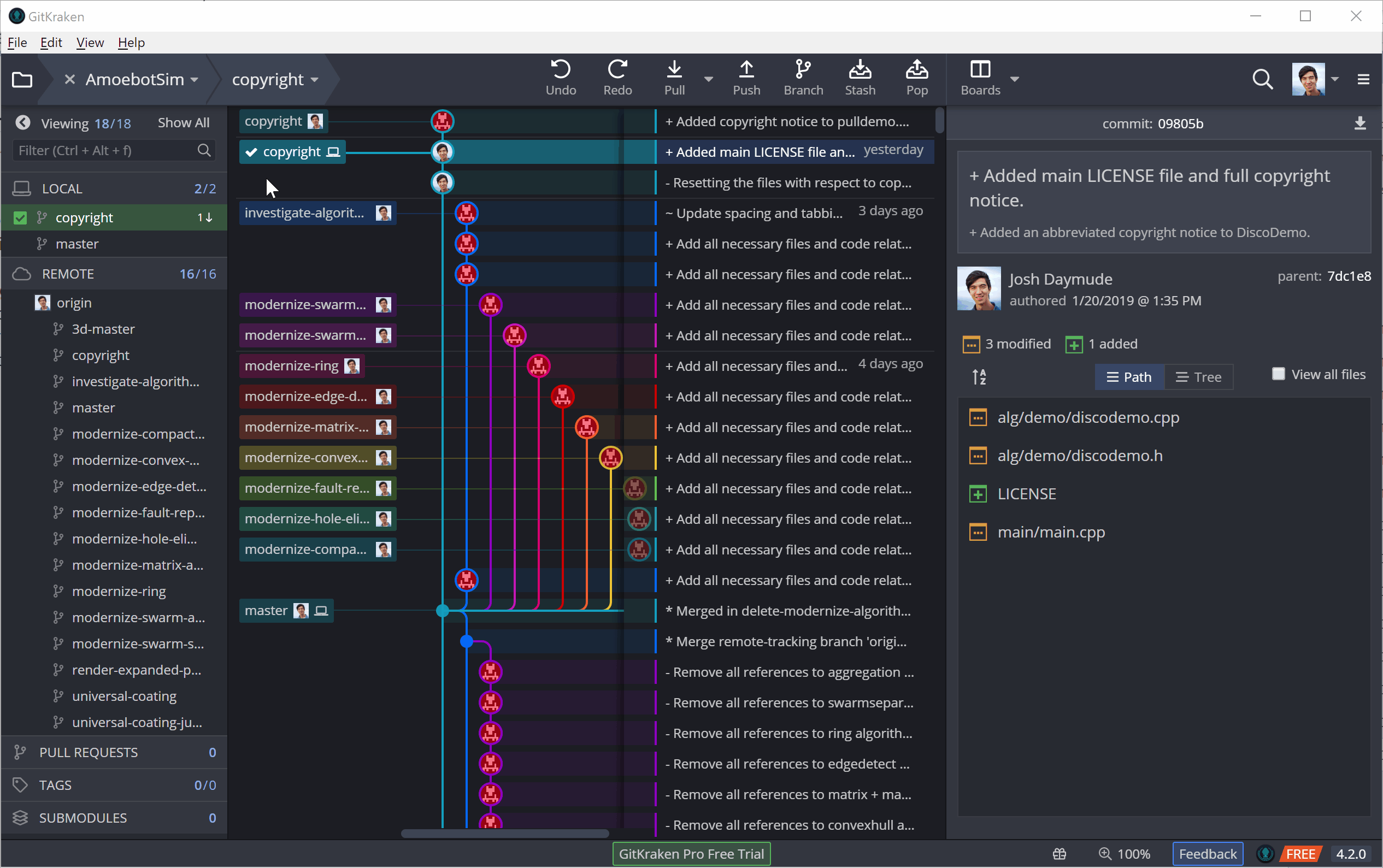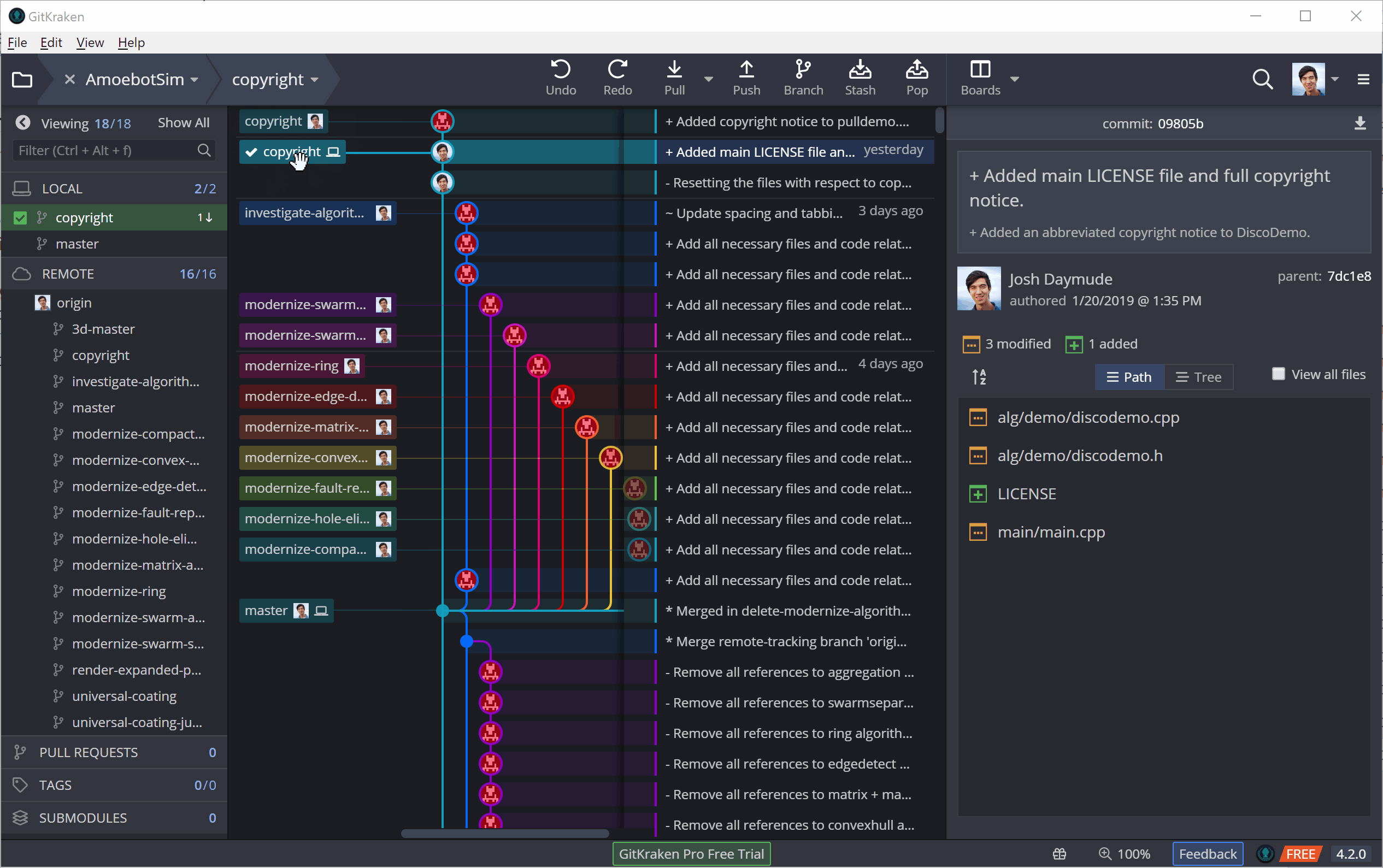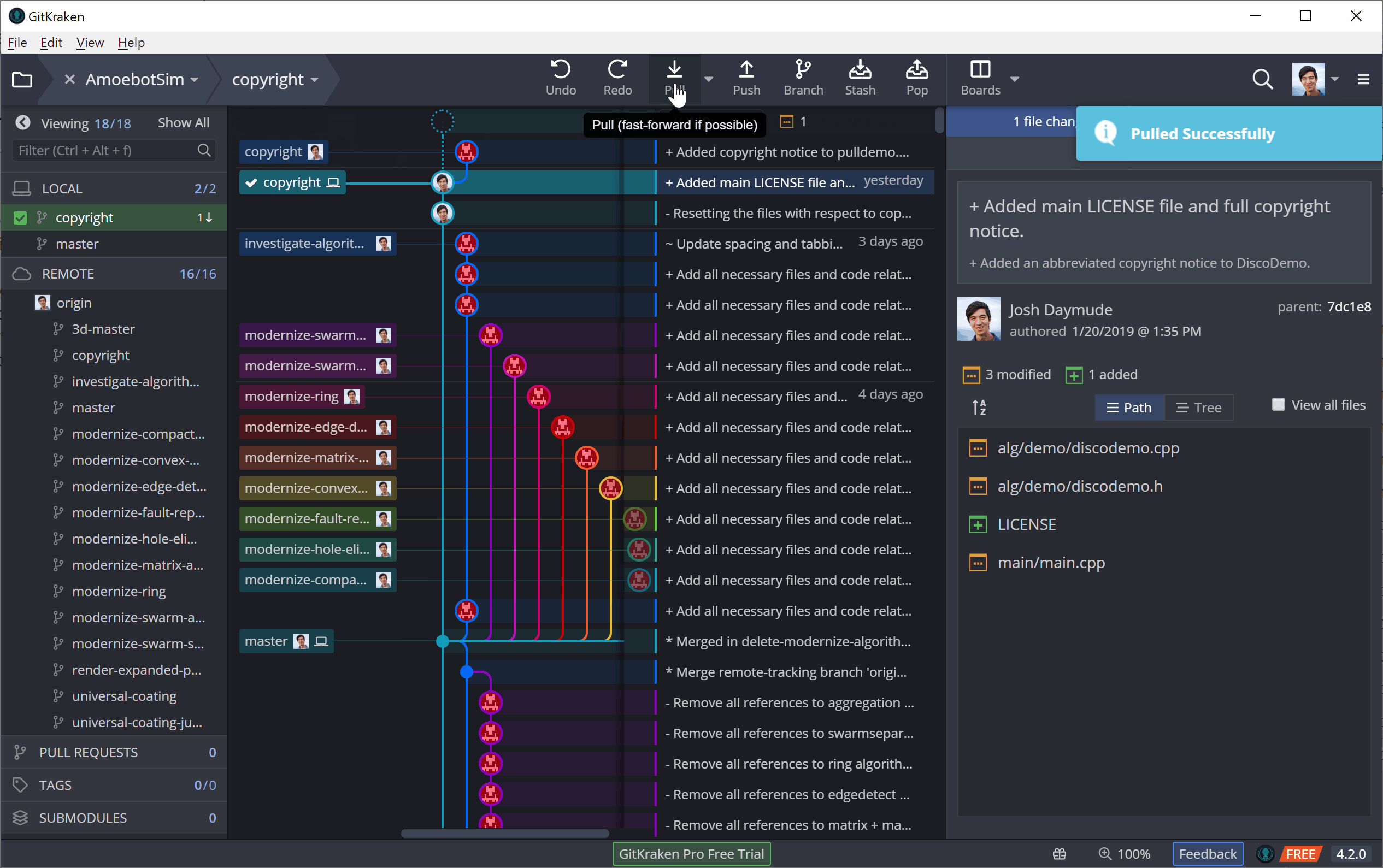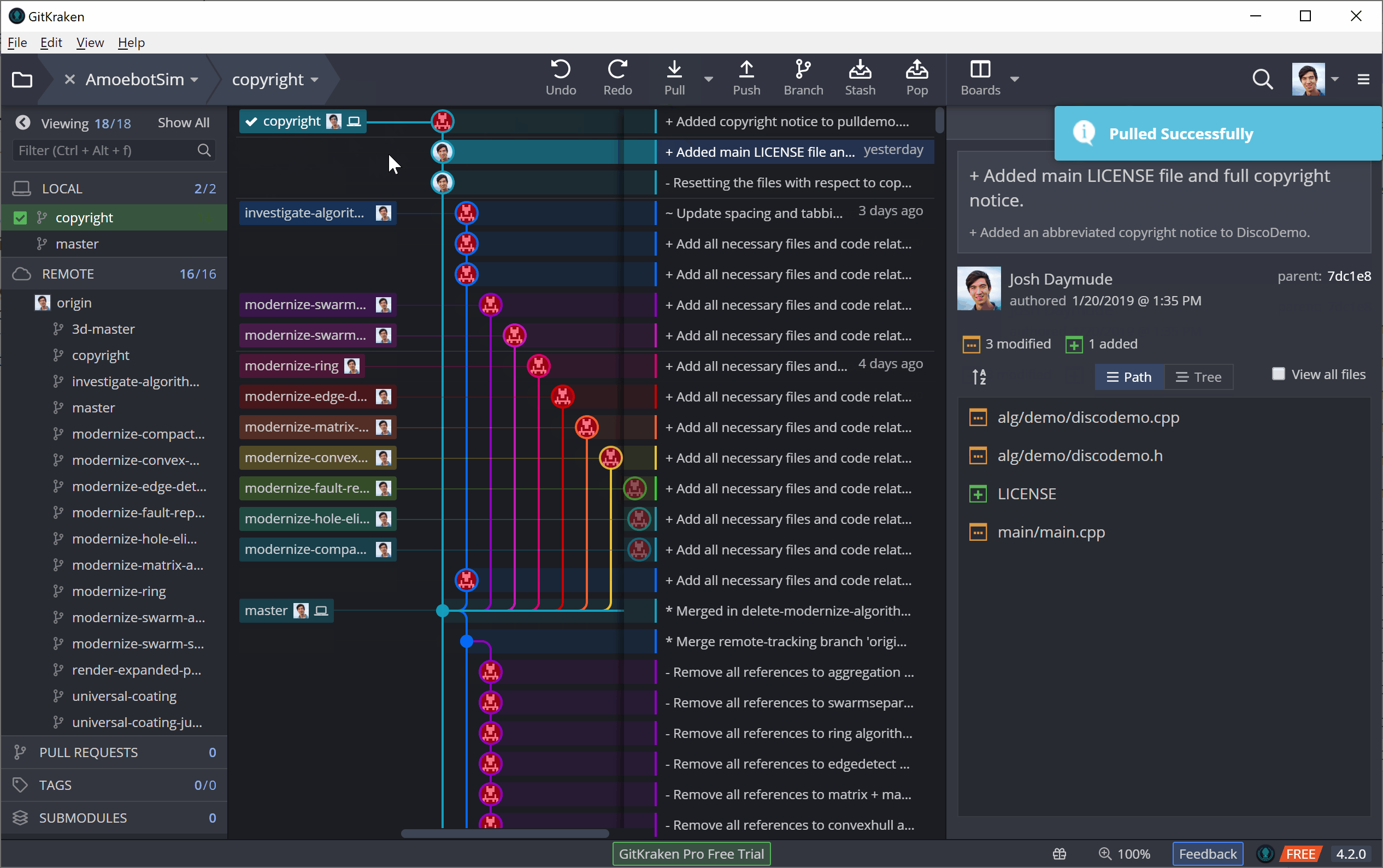
Git Out There
I’ve covered the rudimentary operations of Git and how to do them in GitKraken, but there’s much more to learn! In a future post I hope to cover branch/fork-based workflows, pull requests, and rebasing, all of which can play a role in using Git for larger projects.
As always, I welcome your feedback and questions. Happy coding!
Joshua J. Daymude
Assistant Professor, SCAI & CBSS
I am a Christian and assistant professor in computer science studying collective emergent behavior and programmable matter through the lens of distributed computing, stochastic processes, and bio-inspired algorithms. I also love gaming and playing music.